Team 2: Scott Clay, Kevin Macfarlane, John Pace, Devin Piner
Use the download links in each section to download a zipped folder of the
respective code files, or download all code with the link below.
* At 5:10 PM on Mon 12/09/2019, the CUDA files were updated. We found a bug in processing for
matrices larger than 1024. Please re-download the updated CUDA files for testing.
Download CUDA
Download All Code
Download Presentation
How to Run Code:
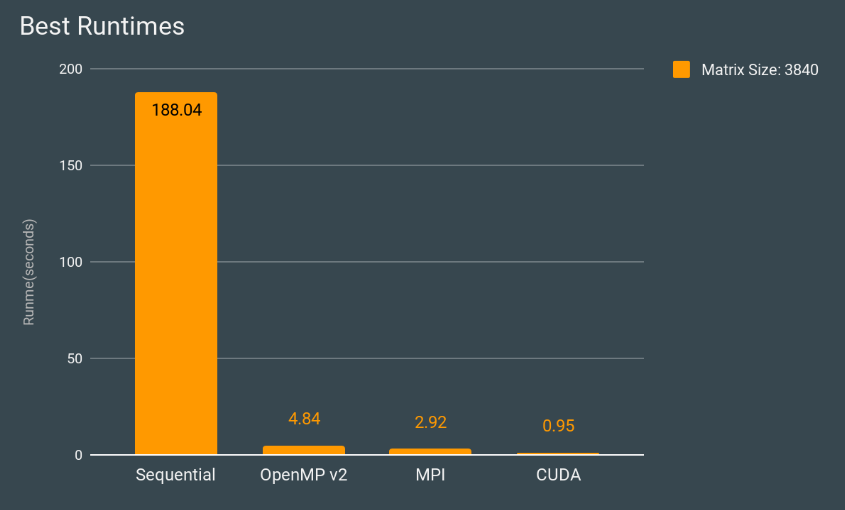
We found the best matrix size for comparison testing to be 3840, so this is the
recommended size to compare runtimes. If a different matrix size is selected, keep
in mind that it must be a multiple of 48 for the mpi code.
We've written custom scripts to make it easier to compile and run
our code. Please see compile and run instructions for each platform in their respective
sections below.
Sequential
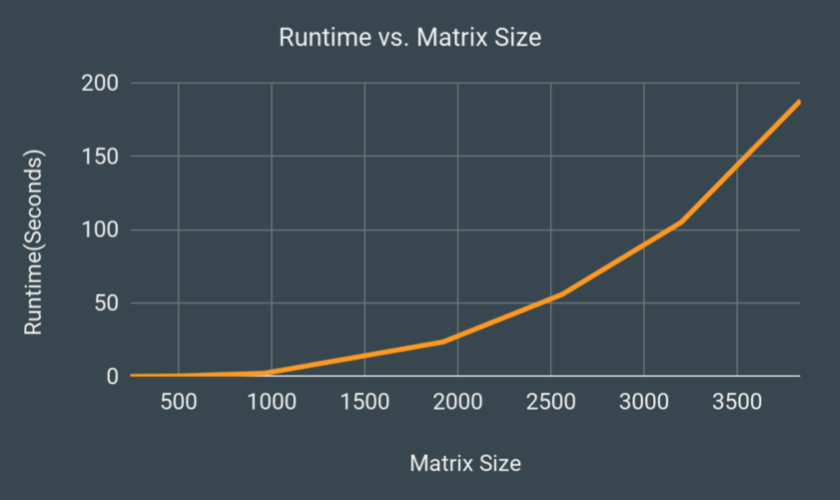
Download Sequential CodeOur sequential baseline in C++. This performs row reductions on matrix a, slowly turning it into matrix U, while storing the coefficient multiplies to fill in matrix L. LU decomposition on a matrix of size 1920 should take around 23 seconds, and size 3840 will take around 3 minutes.
How to run:Give permissions to custom scripts:
- chmod 755 c_seq r_seq
- ./c_seq
- ./r_seq <matrix_size> <print(optional)>
- Notes:
- 1 = print, 0 = not print (default), matrix must be 9x9 or smaller
When job is finished, check results using:
- cat slurm_output.<job_id>
Results:
OpenMP
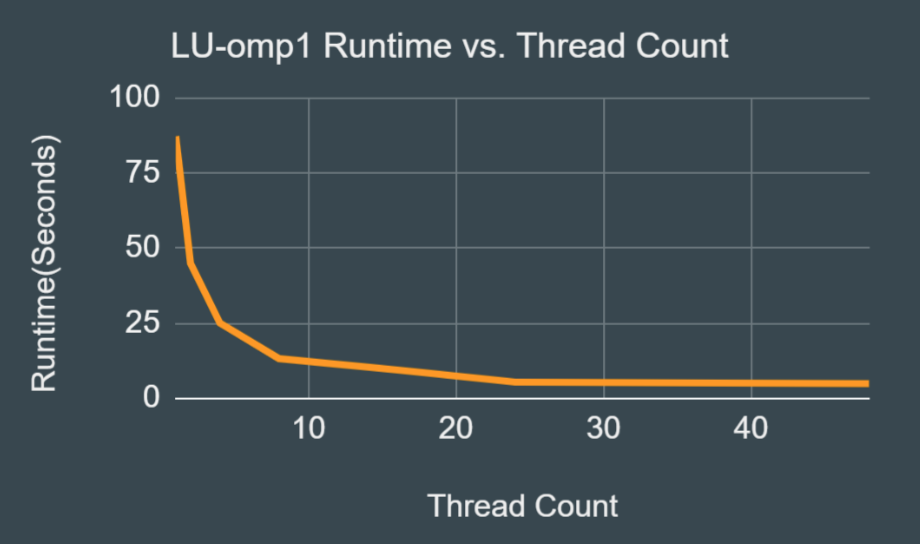
Download OpenMP CodeUses shared matrices and dynamic scheduling to perform the LU decomposition. Using 16 threads with a matrix size of 3840 this should take around 9 seconds, and with 48 threads should take around 5 seconds.
How to run:Give permissions to custom scripts:
- chmod 755 c_omp r_omp
Compile source code using:
- ./c_omp
Run using:
- ./r_omp <matrix_size> <nthreads> <print(optional)>
- Notes:
- 1 = print, 0 = not print (default), matrix must be 9x9 or smaller
- nthreads is a value between 1 - 48
When job is finished, check results using:
- cat slurm_output.<job_id>
Results:
MPI
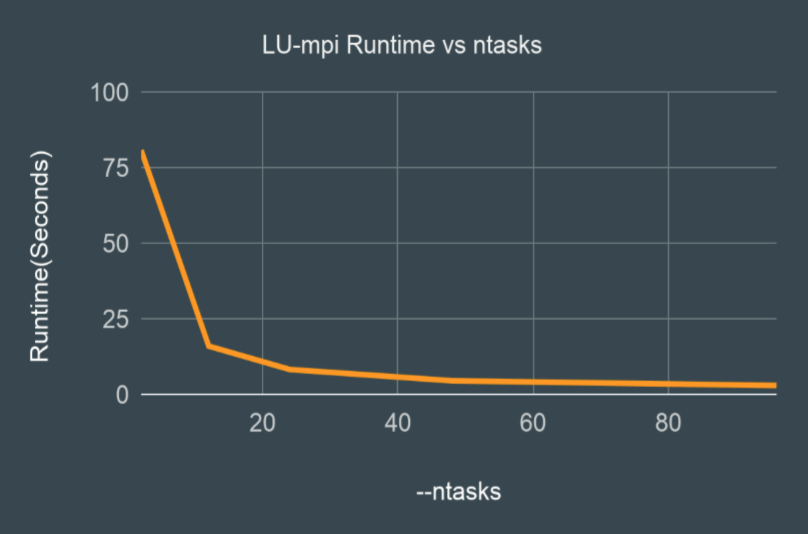
Download MPI CodeUses MPI_Bcast to send coefficient multipliers to processes. Also uses MPI_Send and MPI_Recv to send data portions of matrix a to processes. With a matrix size of 3840, using ntasks=24 and tasks-per-node=24, this should take around 8 seconds. With ntasks=96 and tasks-per-node=24 this should run in under 3 seconds.
How to run:
Give permissions to custom scripts:
- chmod 755 c_mpi r_mpi
Compile source code using:
- ./c_mpi
Run using:
- ./r_mpi <size> <print(optional)>
- Notes:
- 1 = print, 0 = not print (default), matrix must be 9x9 or smaller
- Change ntasks and tasks-per-node in mpi_slurm.sh (default values are ntasks=48, tasks-per-node=24)
- Matrix size must be a multiple of ntasks
When job is finished, check results using:
- cat slurm_output.<job_id>
Results:
CUDA
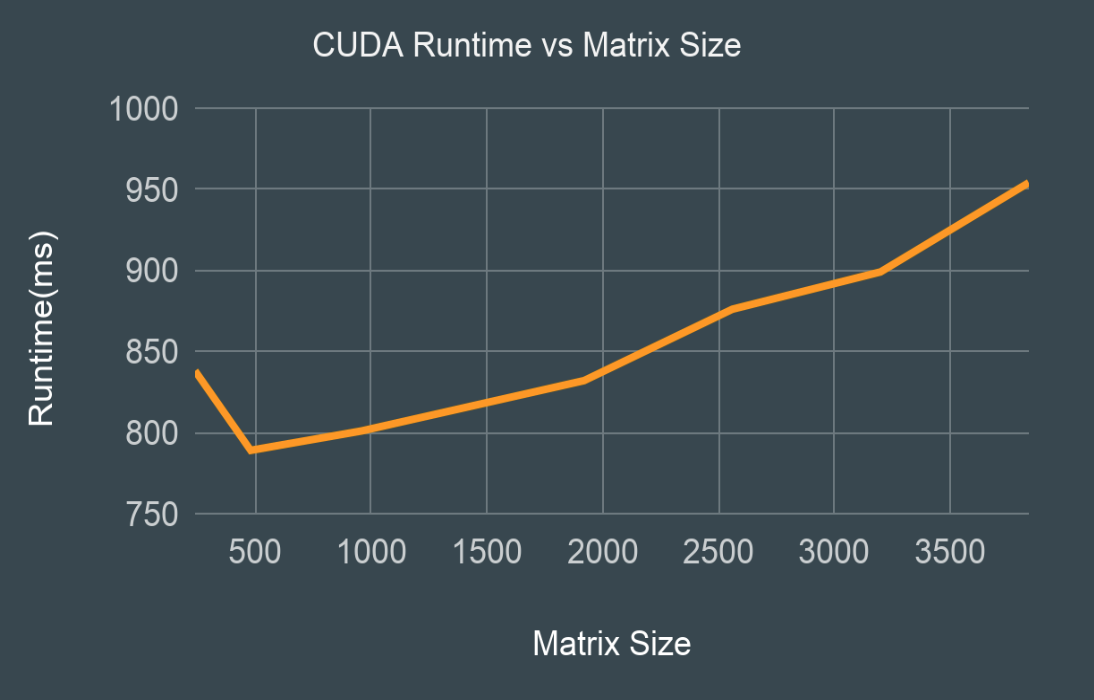
Download CUDA CodeWith matrix size 3840, decomposition should be completed in about 950 ms. It will take longer to run than the runtime shown in results due to memory allocation and communication between the CPU and GPU before and after processing.
How to run:
Give permissions to custom scripts:
- chmod 755 c_gpu r_gpu
Compile source code using:
- ./c_gpu
Run using:
- ./r_gpu <size> <seed> <print(optional)>
- Notes:
- 1 = print, 0 = not print (default), matrix must be 9x9 or smaller
- We used 343 for the seed, you may use any random positive integer
When job is finished, check results using:
- cat slurm_output.<job_id>
Results:
Overall Results